Let’s look at one more way to solve the equation 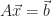


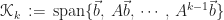
Krylov subspace methods are efficient and popular iterative methods for solving large, sparse linear systems. When 
![\left\{\begin{array}{l} A^{T} = A \\[12pt] \vec{x}^{T}A\vec{x} > 0,\,\,\,\forall\,\vec{x} \neq \vec{0}, \end{array}\right.](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bl%7D+A%5E%7BT%7D+%3D+A+%5C%5C%5B12pt%5D+%5Cvec%7Bx%7D%5E%7BT%7DA%5Cvec%7Bx%7D+%3E+0%2C%5C%2C%5C%2C%5C%2C%5Cforall%5C%2C%5Cvec%7Bx%7D+%5Cneq+%5Cvec%7B0%7D%2C+%5Cend%7Barray%7D%5Cright.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
we can use a Krylov subspace method called Conjugate Gradient (CG).
Today, let’s find out how CG works and use it to solve 2D Poisson’s equation.
4. Conjugate Gradient
a. Creating iterates
Let 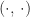

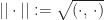
How Krylov subspace methods work is simple. We will approximate the exact solution 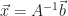
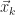
![\begin{array}{l} \mbox{1.}\,\,\,\vec{x}_{k} \in \mathscr{K}_{k} \\[12pt] \mbox{2.}\,\,\,||\vec{x}_{k} - \vec{x}|| = \min\limits_{\vec{y}\,\in\,\mathscr{K}_{k}}\,||\vec{y} - \vec{x}||.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bl%7D+%5Cmbox%7B1.%7D%5C%2C%5C%2C%5C%2C%5Cvec%7Bx%7D_%7Bk%7D+%5Cin+%5Cmathscr%7BK%7D_%7Bk%7D+%5C%5C%5B12pt%5D+%5Cmbox%7B2.%7D%5C%2C%5C%2C%5C%2C%7C%7C%5Cvec%7Bx%7D_%7Bk%7D+-+%5Cvec%7Bx%7D%7C%7C+%3D+%5Cmin%5Climits_%7B%5Cvec%7By%7D%5C%2C%5Cin%5C%2C%5Cmathscr%7BK%7D_%7Bk%7D%7D%5C%2C%7C%7C%5Cvec%7By%7D+-+%5Cvec%7Bx%7D%7C%7C.%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
In other words, when measured in the norm 
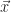
(For initialization, we will take 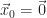

The optimality condition above is the same as the orthogonality condition 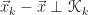
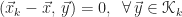
Lemma 1.
The orthogonality condition and the fact that
imply two things. At every iteration
,
![\begin{array}{l} \mbox{1.}\,\,\,\vec{x}_{k} - \vec{x}_{k - 1} \in \mathscr{K}_{k} \\[12pt] \mbox{2.}\,\,\,\vec{x}_{k} - \vec{x}_{k - 1} \perp \mathscr{K}_{k - 1}.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bl%7D+%5Cmbox%7B1.%7D%5C%2C%5C%2C%5C%2C%5Cvec%7Bx%7D_%7Bk%7D+-+%5Cvec%7Bx%7D_%7Bk+-+1%7D+%5Cin+%5Cmathscr%7BK%7D_%7Bk%7D+%5C%5C%5B12pt%5D+%5Cmbox%7B2.%7D%5C%2C%5C%2C%5C%2C%5Cvec%7Bx%7D_%7Bk%7D+-+%5Cvec%7Bx%7D_%7Bk+-+1%7D+%5Cperp+%5Cmathscr%7BK%7D_%7Bk+-+1%7D.%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Proof.
First, note that the vector

represents the decrease in error over 1 iteration.
Since 

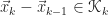
Furthermore, for any 

■
b. Creating residuals
Next, we select a vector 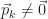
![\begin{array}{l} \mbox{1.}\,\,\,\vec{p}_{k} \in \mathscr{K}_{k} \\[12pt] \mbox{2.}\,\,\,\vec{p}_{k} \perp \mathscr{K}_{k - 1}.\end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bl%7D+%5Cmbox%7B1.%7D%5C%2C%5C%2C%5C%2C%5Cvec%7Bp%7D_%7Bk%7D+%5Cin+%5Cmathscr%7BK%7D_%7Bk%7D+%5C%5C%5B12pt%5D+%5Cmbox%7B2.%7D%5C%2C%5C%2C%5C%2C%5Cvec%7Bp%7D_%7Bk%7D+%5Cperp+%5Cmathscr%7BK%7D_%7Bk+-+1%7D.%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
(For initialization, we will take 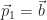
The vector 
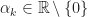

We now have a way to compute the best approximation

This holds, provided we have a search direction 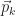
Lemma 2.
The coefficient
is given by,
,
where
is the residual.
Proof.
We have the equation,
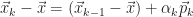
On each side, take the inner product with
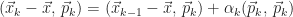
Since 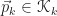

Note, 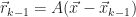
■
Lemma 3.
The residuals are related in the following manner:
.
Proof.
Apply

■
c. Creating search directions
We will now construct the search direction 
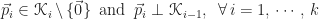
Thus, if

then 
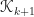
We can create such a sequence using Gram-Schmidt method! Specifically, 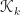
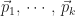

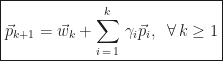
Then, we orthogonalize
Lemma 4.
In the
are given by,
.
Proof.
Given the equation,

we can take the inner product with 
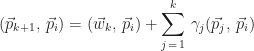
Since 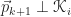

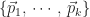

We can now solve for

■
Isn’t it cool to work backwards and see the motivations? We just need to figure out how to choose
d. SPD
So far, we have not used the fact that
Lemma 5.
If
defines an inner product for
gives us a norm, called the
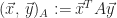
Proof.
Let’s show that, for all vectors 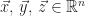

Symmetric:
![\begin{aligned} (\vec{x},\,\vec{y})_{A} &= \vec{x}^{T}A\vec{y} \\[12pt] &= \vec{x}^{T}A^{T}\vec{y} \\[12pt] &= (A\vec{x})^{T}\vec{y} \\[12pt] &= \vec{y}^{T}(A\vec{x}) \\[12pt] &= (\vec{y},\,\vec{x})_{A}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%28%5Cvec%7Bx%7D%2C%5C%2C%5Cvec%7By%7D%29_%7BA%7D+%26%3D+%5Cvec%7Bx%7D%5E%7BT%7DA%5Cvec%7By%7D+%5C%5C%5B12pt%5D+%26%3D+%5Cvec%7Bx%7D%5E%7BT%7DA%5E%7BT%7D%5Cvec%7By%7D+%5C%5C%5B12pt%5D+%26%3D+%28A%5Cvec%7Bx%7D%29%5E%7BT%7D%5Cvec%7By%7D+%5C%5C%5B12pt%5D+%26%3D+%5Cvec%7By%7D%5E%7BT%7D%28A%5Cvec%7Bx%7D%29+%5C%5C%5B12pt%5D+%26%3D+%28%5Cvec%7By%7D%2C%5C%2C%5Cvec%7Bx%7D%29_%7BA%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Notice how we used symmetry of the Euclidean inner product.
Bilinear:
![\begin{aligned} (\alpha\vec{x} + \beta\vec{y},\,\vec{z})_{A} &= (\alpha\vec{x} + \beta\vec{y})^{T}A\vec{z} \\[12pt] &= \alpha(\vec{x}^{T}A\vec{z}) + \beta(\vec{y}^{T}A\vec{z}) \\[12pt] &= \alpha(\vec{x},\,\vec{z})_{A} + \beta(\vec{y},\,\vec{z})_{A}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%28%5Calpha%5Cvec%7Bx%7D+%2B+%5Cbeta%5Cvec%7By%7D%2C%5C%2C%5Cvec%7Bz%7D%29_%7BA%7D+%26%3D+%28%5Calpha%5Cvec%7Bx%7D+%2B+%5Cbeta%5Cvec%7By%7D%29%5E%7BT%7DA%5Cvec%7Bz%7D+%5C%5C%5B12pt%5D+%26%3D+%5Calpha%28%5Cvec%7Bx%7D%5E%7BT%7DA%5Cvec%7Bz%7D%29+%2B+%5Cbeta%28%5Cvec%7By%7D%5E%7BT%7DA%5Cvec%7Bz%7D%29+%5C%5C%5B12pt%5D+%26%3D+%5Calpha%28%5Cvec%7Bx%7D%2C%5C%2C%5Cvec%7Bz%7D%29_%7BA%7D+%2B+%5Cbeta%28%5Cvec%7By%7D%2C%5C%2C%5Cvec%7Bz%7D%29_%7BA%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Since the
Positive-definite:
Because
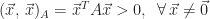
The 
■
The key thing to realize is that Sections 4a – 4c are valid for any nonsingular matrix 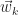
Let’s summarize what we learned so far using the
We want to arrive at the solution

By sheer luck (or well-planning), the residual 

In particular, this means the residuals are orthogonal to each other. Hence the name Conjugate Gradient (“orthogonal residuals” didn’t sound good).
Given a best approximation 

where,

We can also find the residual:
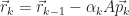
Notice that 
To continue the iteration, we decide on a search direction for some
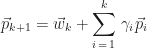
where,

e. Creating offshoots
There are a few candidates for 

so that all but one of the coefficients
Lemma 6.
When
,
.
Proof.
First, let’s check that 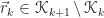
We know that the residual 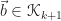
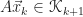
Moreover, 

■
Lemma 7.
When
, and
![\begin{array}{c} \displaystyle\alpha_{k} = \frac{\vec{r}_{k - 1}^{T}\vec{r}_{k - 1}}{\vec{p}_{k}A\vec{p}_{k}} \\[20pt] \displaystyle\gamma_{k} = \frac{\vec{r}_{k}^{T}\vec{r}_{k}}{\vec{r}_{k - 1}^{T}\vec{r}_{k - 1}} \\[28pt] \vec{p}_{k + 1} = \vec{r}_{k} + \gamma_{k}\vec{p}_{k}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bc%7D+%5Cdisplaystyle%5Calpha_%7Bk%7D+%3D+%5Cfrac%7B%5Cvec%7Br%7D_%7Bk+-+1%7D%5E%7BT%7D%5Cvec%7Br%7D_%7Bk+-+1%7D%7D%7B%5Cvec%7Bp%7D_%7Bk%7DA%5Cvec%7Bp%7D_%7Bk%7D%7D+%5C%5C%5B20pt%5D+%5Cdisplaystyle%5Cgamma_%7Bk%7D+%3D+%5Cfrac%7B%5Cvec%7Br%7D_%7Bk%7D%5E%7BT%7D%5Cvec%7Br%7D_%7Bk%7D%7D%7B%5Cvec%7Br%7D_%7Bk+-+1%7D%5E%7BT%7D%5Cvec%7Br%7D_%7Bk+-+1%7D%7D+%5C%5C%5B28pt%5D+%5Cvec%7Bp%7D_%7Bk+%2B+1%7D+%3D+%5Cvec%7Br%7D_%7Bk%7D+%2B+%5Cgamma_%7Bk%7D%5Cvec%7Bp%7D_%7Bk%7D.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Proof.
The formula for
From Section 4d, we know that,
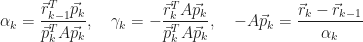
By orthogonality, the numerator of

As for
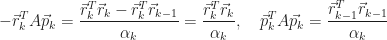
■
f. Summary
The pseudocode for CG looks like this:
% Initialize
x0 = zeros(n, 1), r0 = b, p1 = b;
for k = 1 : numIterations
% Sparse matrix-vector multiply
Ap1 = A * p1;
% Find alpha
alpha1 = (r0' * r0) / (p1' * Ap1);
% Find the iterate
x1 = x0 + alpha1 * p1;
% Find the residual
r1 = r0 - alpha1 * Ap1;
% Find gamma
gamma1 = (r1' * r1) / (r0' * r0);
% Find the search direction
p2 = r1 + gamma1 * p1;
% Update the iterates
x0 = x1;
r0 = r1;
p1 = p2;
end
Notice how we only need a sparse matrix-vector multiply, a vector-scalar multiply (axpy), and a dot product to solve a matrix equation. This is the power of iterative methods. We can make our code more efficient by reusing variables:
% Initialize
x = zeros(n, 1), r = b, p = b;
r_dot = r' * r;
for k = 1 : numIterations
% Sparse matrix-vector multiply
Ap = A * p;
% Find alpha and initialize gamma
alpha = r_dot / (p' * Ap);
gamma = r_dot;
% Find the iterate
x = x + alpha * p;
% Find the residual
r = r - alpha * Ap;
r_dot = r' * r;
% Find gamma
gamma = r_dot / gamma;
% Find the search direction
p = r + gamma * p;
end
5. Example
Let’s go back to 2D Poisson’s equation on a unit square domain, with homogeneous Dirichlet BC. Our RHS function is given by,

and we choose 

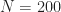
Stunningly, CG converges in 1 iteration! As far as iterative methods go, you can’t do better than that.
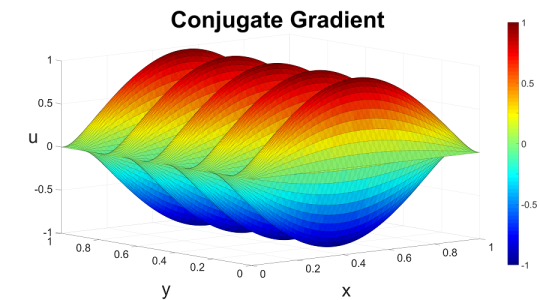
The question is how? The RHS function that I chose makes the Poisson’s equation an eigenfunction problem. Even at the discrete level, the RHS vector 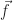
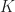
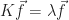
As a result, in the first iteration,
![\begin{array}{l} \displaystyle\alpha_{1} \,=\, \frac{\vec{f}^{T}\vec{f}}{\vec{f}^{T}K\vec{f}} \,=\, \frac{1}{\lambda} \\[20pt] \displaystyle\vec{r}_{1} \,=\, \vec{f} - \alpha_{1}K\vec{f} \,=\, \vec{f} - \frac{1}{\lambda} \cdot \lambda\vec{f} \,=\, \vec{0}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bl%7D+%5Cdisplaystyle%5Calpha_%7B1%7D+%5C%2C%3D%5C%2C+%5Cfrac%7B%5Cvec%7Bf%7D%5E%7BT%7D%5Cvec%7Bf%7D%7D%7B%5Cvec%7Bf%7D%5E%7BT%7DK%5Cvec%7Bf%7D%7D+%5C%2C%3D%5C%2C+%5Cfrac%7B1%7D%7B%5Clambda%7D+%5C%5C%5B20pt%5D+%5Cdisplaystyle%5Cvec%7Br%7D_%7B1%7D+%5C%2C%3D%5C%2C+%5Cvec%7Bf%7D+-+%5Calpha_%7B1%7DK%5Cvec%7Bf%7D+%5C%2C%3D%5C%2C+%5Cvec%7Bf%7D+-+%5Cfrac%7B1%7D%7B%5Clambda%7D+%5Ccdot+%5Clambda%5Cvec%7Bf%7D+%5C%2C%3D%5C%2C+%5Cvec%7B0%7D.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Talk about luck (or well-planning)!
Notes
A big thanks goes to Dr. Ye, one of my teachers at Kentucky. He instilled my passion for numerical linear algebra and applications thereof. To learn additional iterative methods, I recommend reading his paper linked below.
You can find the code in its entirety here:
References
[1] Isaac Lee, lecture notes (2011).
[2] Qiang Ye, Deriving Optimal Krylov Subspace Methods.
[3] Qiang Ye, lecture notes (2009).
