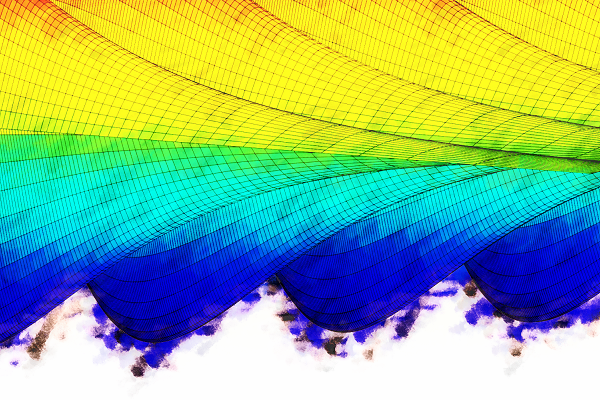
Last time, we looked at 2D Poisson’s equation and discussed how to arrive at a matrix equation using the finite difference method. The matrix, which represents the discrete Laplace operator, is sparse, so we can use an iterative method to solve the equation efficiently.
Today, we will look at Jacobi, Gauss-Seidel, Successive Over-Relaxation (SOR), and Symmetric SOR (SSOR), and a couple of related techniques—red-black ordering and Chebyshev acceleration. In addition, we will analyze the convergence of each method for the Poisson’s equation, both analytically and numerically.
2. Classical iterative methods
Recall that we placed 


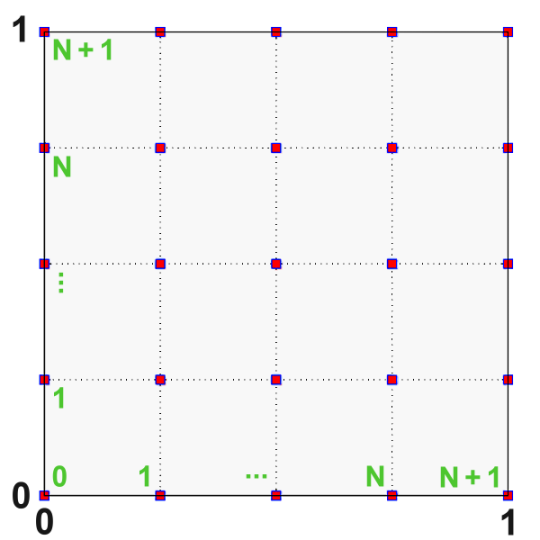
Each row in the equation 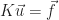

where 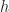
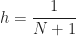
We also looked at the general equation 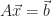
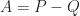
Note that 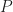
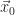

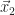
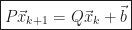
Lastly, we defined the matrix,

and concluded that the iterative method converges from any initial guess, if and only if, the spectral radius 
Before we move on, let us define the rate of convergence:
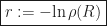
The smaller the spectral radius of 
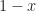
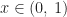
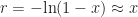
When 
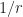


c. Jacobi
For Jacobi method, we split 
![\left\{\begin{array}{l} P := D \\[12pt] Q := L + U, \end{array}\right.](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bl%7D+P+%3A%3D+D+%5C%5C%5B12pt%5D+Q+%3A%3D+L+%2B+U%2C+%5Cend%7Barray%7D%5Cright.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where,
![\begin{array}{rcl} D & = & \mbox{diagonals of }A\mbox{ (assume nonzero diagonals)} \\[12pt] -L & = & \mbox{strictly lower triangular part of }A \\[12pt] -U & = & \mbox{strictly upper triangular part of }A. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+D+%26+%3D+%26+%5Cmbox%7Bdiagonals+of+%7DA%5Cmbox%7B+%28assume+nonzero+diagonals%29%7D+%5C%5C%5B12pt%5D+-L+%26+%3D+%26+%5Cmbox%7Bstrictly+lower+triangular+part+of+%7DA+%5C%5C%5B12pt%5D+-U+%26+%3D+%26+%5Cmbox%7Bstrictly+upper+triangular+part+of+%7DA.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Let’s look at the fixed-point equation entry-wise:
![\begin{array}{c} D\vec{x}_{k + 1} = (L + U)\vec{x}_{k} + \vec{b} \\[12pt] \Updownarrow \\[12pt] \displaystyle a_{ii}x_{i}^{(k + 1)} = -\sum_{j\,\neq\,i}^{n}\,a_{ij}x_{j}^{(k)} + b_{i}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bc%7D+D%5Cvec%7Bx%7D_%7Bk+%2B+1%7D+%3D+%28L+%2B+U%29%5Cvec%7Bx%7D_%7Bk%7D+%2B+%5Cvec%7Bb%7D+%5C%5C%5B12pt%5D+%5CUpdownarrow+%5C%5C%5B12pt%5D+%5Cdisplaystyle+a_%7Bii%7Dx_%7Bi%7D%5E%7B%28k+%2B+1%29%7D+%3D+-%5Csum_%7Bj%5C%2C%5Cneq%5C%2Ci%7D%5E%7Bn%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k%29%7D+%2B+b_%7Bi%7D.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Note that, for efficiency, we do not invert the matrix 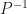
Since the diagonals are nonzero, we can divide both sides of the equation by 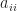
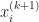


![\displaystyle\boxed{x_{i}^{(k + 1)} = \frac{1}{a_{ii}}\left[-\sum_{j\,\neq\,i}^{n}\,a_{ij}x_{j}^{(k)} + b_{i}\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cboxed%7Bx_%7Bi%7D%5E%7B%28k+%2B+1%29%7D+%3D+%5Cfrac%7B1%7D%7Ba_%7Bii%7D%7D%5Cleft%5B-%5Csum_%7Bj%5C%2C%5Cneq%5C%2Ci%7D%5E%7Bn%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k%29%7D+%2B+b_%7Bi%7D%5Cright%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Notice how we use information from the 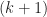
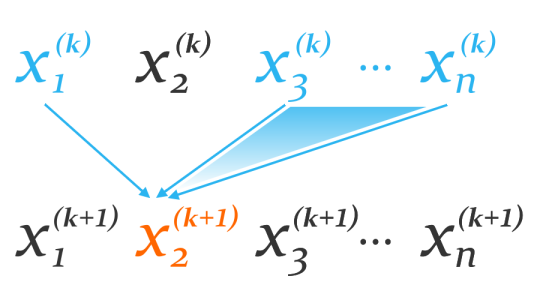
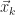 to find those of the next .
to find those of the next .For Poisson’s equation, the diagonals of 
Jacobi, 2D Poisson’s equation
![\displaystyle\boxed{u_{i,\,j}^{(k + 1)} = \frac{1}{4}\left[u_{i-1,\,j}^{(k)} + u_{i+1,\,j}^{(k)} + u_{i,\,j-1}^{(k)} + u_{i,\,j+1}^{(k)} + h^{2}f_{ij}\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cboxed%7Bu_%7Bi%2C%5C%2Cj%7D%5E%7B%28k+%2B+1%29%7D+%3D+%5Cfrac%7B1%7D%7B4%7D%5Cleft%5Bu_%7Bi-1%2C%5C%2Cj%7D%5E%7B%28k%29%7D+%2B+u_%7Bi%2B1%2C%5C%2Cj%7D%5E%7B%28k%29%7D+%2B+u_%7Bi%2C%5C%2Cj-1%7D%5E%7B%28k%29%7D+%2B+u_%7Bi%2C%5C%2Cj%2B1%7D%5E%7B%28k%29%7D+%2B+h%5E%7B2%7Df_%7Bij%7D%5Cright%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
As we can see below, it’s easy to implement Jacobi method.
% Set initial guess u
u = [...];
% Set temporary variable
uNew = zeros(N + 2);
for k = 1 : numIterations
% Natural ordering
for j = 2 : (N + 1)
for i = 2 : (N + 1)
uNew(i, j) = 1/4 * (u(i - 1, j) + u(i + 1, j) + u(i, j - 1) + u(i, j + 1) + h^2*f(i, j));
end
end
% Update iterate
u = uNew;
end
Finally, let’s analyze the convergence of Jacobi method for Poisson’s equation. We use the fact that the eigenvalues of

Convergence of Jacobi, 2D Poisson’s equation
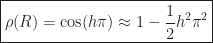
Proof.
First, let’s find the eigenvalues of 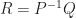
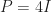
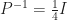
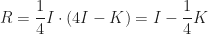
Hence, we can find the eigenvalues of
![\displaystyle\begin{aligned} \lambda_{i,\,j}(R) &= 1 - \frac{1}{4}\lambda_{i,\,j}(K) \\[12pt] &= \frac{1}{2}\cos(ih\pi) + \frac{1}{2}\cos(jh\pi). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cbegin%7Baligned%7D+%5Clambda_%7Bi%2C%5C%2Cj%7D%28R%29+%26%3D+1+-+%5Cfrac%7B1%7D%7B4%7D%5Clambda_%7Bi%2C%5C%2Cj%7D%28K%29+%5C%5C%5B12pt%5D+%26%3D+%5Cfrac%7B1%7D%7B2%7D%5Ccos%28ih%5Cpi%29+%2B+%5Cfrac%7B1%7D%7B2%7D%5Ccos%28jh%5Cpi%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The spectral radius 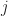

■
Since 
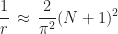
additional iterations. Can we do better?
d. Gauss-Seidel
This time, we split 
![\left\{\begin{array}{l} P := D - L \\[12pt] Q := U, \end{array}\right.](https://s0.wp.com/latex.php?latex=%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bl%7D+P+%3A%3D+D+-+L+%5C%5C%5B12pt%5D+Q+%3A%3D+U%2C+%5Cend%7Barray%7D%5Cright.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
where 
Let’s analyze the action of
![\begin{array}{c} (D - L)\vec{x}_{k + 1} = U\vec{x}_{k} + \vec{b} \\[12pt] \Updownarrow \\[12pt] \displaystyle \sum_{j\,=\,1}^{i}\,a_{ij}x_{j}^{(k + 1)} = -\sum_{j\,=\,i+1}^{n}\,a_{ij}x_{j}^{(k)} + b_{i}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bc%7D+%28D+-+L%29%5Cvec%7Bx%7D_%7Bk+%2B+1%7D+%3D+U%5Cvec%7Bx%7D_%7Bk%7D+%2B+%5Cvec%7Bb%7D+%5C%5C%5B12pt%5D+%5CUpdownarrow+%5C%5C%5B12pt%5D+%5Cdisplaystyle+%5Csum_%7Bj%5C%2C%3D%5C%2C1%7D%5E%7Bi%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k+%2B+1%29%7D+%3D+-%5Csum_%7Bj%5C%2C%3D%5C%2Ci%2B1%7D%5E%7Bn%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k%29%7D+%2B+b_%7Bi%7D.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Now comes the clever idea. By the time we compute 
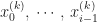
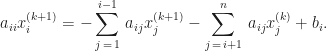
Finally, we divide both sides of the equation by 
![\displaystyle \boxed{x_{i}^{(k + 1)} = \frac{1}{a_{ii}}\left[-\sum_{j\,=\,1}^{i-1}\,a_{ij}x_{j}^{(k + 1)} - \sum_{j\,=\,i+1}^{n}\,a_{ij}x_{j}^{(k)} + b_{i}\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cboxed%7Bx_%7Bi%7D%5E%7B%28k+%2B+1%29%7D+%3D+%5Cfrac%7B1%7D%7Ba_%7Bii%7D%7D%5Cleft%5B-%5Csum_%7Bj%5C%2C%3D%5C%2C1%7D%5E%7Bi-1%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k+%2B+1%29%7D+-+%5Csum_%7Bj%5C%2C%3D%5C%2Ci%2B1%7D%5E%7Bn%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k%29%7D+%2B+b_%7Bi%7D%5Cright%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
We can visualize the similarities and dissimilarities between Jacobi and Gauss-Seidel with the diagram below.
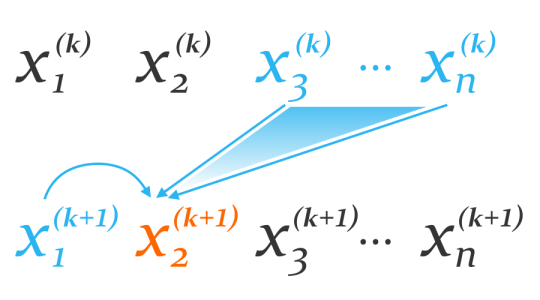 to compute its remaining entries more accurately.
to compute its remaining entries more accurately.Gauss-Seidel, 2D Poisson’s equation
![\displaystyle\boxed{u_{i,\,j}^{(k + 1)} = \frac{1}{4}\left[u_{i-1,\,j}^{(k + 1)} + u_{i+1,\,j}^{(k)} + u_{i,\,j-1}^{(k + 1)} + u_{i,\,j+1}^{(k)} + h^{2}f_{ij}\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cboxed%7Bu_%7Bi%2C%5C%2Cj%7D%5E%7B%28k+%2B+1%29%7D+%3D+%5Cfrac%7B1%7D%7B4%7D%5Cleft%5Bu_%7Bi-1%2C%5C%2Cj%7D%5E%7B%28k+%2B+1%29%7D+%2B+u_%7Bi%2B1%2C%5C%2Cj%7D%5E%7B%28k%29%7D+%2B+u_%7Bi%2C%5C%2Cj-1%7D%5E%7B%28k+%2B+1%29%7D+%2B+u_%7Bi%2C%5C%2Cj%2B1%7D%5E%7B%28k%29%7D+%2B+h%5E%7B2%7Df_%7Bij%7D%5Cright%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Convergence of Gauss-Seidel, 2D Poisson’s equation

Proof.
We use the fact that, 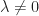


For now, assume that
![\begin{aligned} \rho(R_{GS}) &= \rho(R_{J})^{2} \\[8pt] &\approx \left(1 - \frac{1}{2}h^{2}\pi^{2}\right)^{2} \\[12pt] &\approx 1 - h^{2}\pi^{2}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Crho%28R_%7BGS%7D%29+%26%3D+%5Crho%28R_%7BJ%7D%29%5E%7B2%7D+%5C%5C%5B8pt%5D+%26%5Capprox+%5Cleft%281+-+%5Cfrac%7B1%7D%7B2%7Dh%5E%7B2%7D%5Cpi%5E%7B2%7D%5Cright%29%5E%7B2%7D+%5C%5C%5B12pt%5D+%26%5Capprox+1+-+h%5E%7B2%7D%5Cpi%5E%7B2%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
■
The number of iterations further needed to reduce the error by

which is half of that of Jacobi.
Let’s resolve the caveat. For our problem,
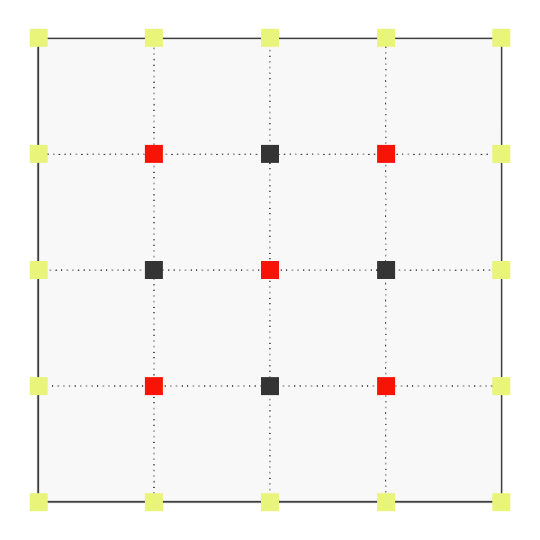
The red points are updated first using the previous iterate, then the black points using the updated red points. Note that Gauss-Seidel does converge if we traverse the points in the natural order. However, we will not achieve optimal convergence. This will also be the case when we look at Successive Over-Relaxation.
We summarize Gauss-Seidel with a pseudocode below. Notice that we no longer need the temporary variable uNew.
% Set initial guess u
u = [...];
for k = 1 : numIterations
% Red points
for j = 2 : (N + 1)
for i = 2 : (N + 1)
if (mod(i + j, 2) == 0)
u(i, j) = 1/4 * (u(i - 1, j) + u(i + 1, j) + u(i, j - 1) + u(i, j + 1) + h^2*f(i, j));
end
end
end
% Black points
for j = 2 : (N + 1)
for i = 2 : (N + 1)
if (mod(i + j, 2) == 1)
u(i, j) = 1/4 * (u(i - 1, j) + u(i + 1, j) + u(i, j - 1) + u(i, j + 1) + h^2*f(i, j));
end
end
end
end
e. Successive Over-Relaxation
Gauss-Seidel takes the current iterate
This is the motivation behind Successive Over-Relaxation (SOR). We take a weighted average of the current iterate 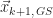
Entry-wise, this means the following:
![\displaystyle \boxed{x_{i}^{(k + 1)} = (1 - \omega)\,x_{i}^{(k)} + \frac{\omega}{a_{ii}}\left[-\sum_{j\,=\,1}^{i-1}\,a_{ij}x_{j}^{(k + 1)} - \sum_{j\,=\,i+1}^{n}\,a_{ij}x_{j}^{(k)} + b_{i}\right]}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cboxed%7Bx_%7Bi%7D%5E%7B%28k+%2B+1%29%7D+%3D+%281+-+%5Comega%29%5C%2Cx_%7Bi%7D%5E%7B%28k%29%7D+%2B+%5Cfrac%7B%5Comega%7D%7Ba_%7Bii%7D%7D%5Cleft%5B-%5Csum_%7Bj%5C%2C%3D%5C%2C1%7D%5E%7Bi-1%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k+%2B+1%29%7D+-+%5Csum_%7Bj%5C%2C%3D%5C%2Ci%2B1%7D%5E%7Bn%7D%5C%2Ca_%7Bij%7Dx_%7Bj%7D%5E%7B%28k%29%7D+%2B+b_%7Bi%7D%5Cright%5D%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Note that, if 
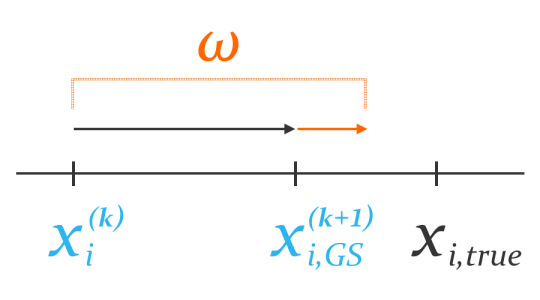
The weight 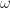
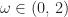


Convergence of SOR
If the matrix
then SOR converges for any

For our problem, we know that

Again, we want a consistently ordered
We summarize SOR for Poisson’s equation below:
SOR, 2D Poisson’s equation
![\boxed{\left\{\begin{array}{l} \displaystyle\omega = \frac{2}{1 + \sin(h\pi)} \\[20pt] \displaystyle u_{i,\,j}^{(k + 1)} = (1 - \omega)\,u_{i,\,j}^{(k)} + \frac{\omega}{4}\left[u_{i-1,\,j}^{(k + 1)} + u_{i+1,\,j}^{(k)} + u_{i,\,j-1}^{(k + 1)} + u_{i,\,j+1}^{(k)} + h^{2}f_{ij}\right] \end{array}\right.}](https://s0.wp.com/latex.php?latex=%5Cboxed%7B%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bl%7D+%5Cdisplaystyle%5Comega+%3D+%5Cfrac%7B2%7D%7B1+%2B+%5Csin%28h%5Cpi%29%7D+%5C%5C%5B20pt%5D+%5Cdisplaystyle+u_%7Bi%2C%5C%2Cj%7D%5E%7B%28k+%2B+1%29%7D+%3D+%281+-+%5Comega%29%5C%2Cu_%7Bi%2C%5C%2Cj%7D%5E%7B%28k%29%7D+%2B+%5Cfrac%7B%5Comega%7D%7B4%7D%5Cleft%5Bu_%7Bi-1%2C%5C%2Cj%7D%5E%7B%28k+%2B+1%29%7D+%2B+u_%7Bi%2B1%2C%5C%2Cj%7D%5E%7B%28k%29%7D+%2B+u_%7Bi%2C%5C%2Cj-1%7D%5E%7B%28k+%2B+1%29%7D+%2B+u_%7Bi%2C%5C%2Cj%2B1%7D%5E%7B%28k%29%7D+%2B+h%5E%7B2%7Df_%7Bij%7D%5Cright%5D+%5Cend%7Barray%7D%5Cright.%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Convergence of SOR, 2D Poisson’s equation
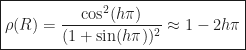
This time, as we refine the domain, the spectral radius approaches 1 only linearly. The number of iterations further needed to reduce the error by
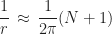
about
f. Symmetric SOR
In Symmetric SOR (SSOR), we take a half-step of SOR in the natural order, then take another half-step of SOR in the reverse order. John Sheldon, who published SSOR in 1955, had gotten inspiration from “a computer which has magnetic tapes which read ‘backward’ as well as ‘forward.'”
SSOR alone does not produce a solution much different from that from SOR. In fact, for every iteration of SSOR, we incur 2 iterations of SOR. However, when we consider an auxiliary problem known as Chebyshev acceleration, SSOR can reach convergence an order of magnitude faster. I won’t explain why Chebyshev acceleration works, but will provide the pseudocode and implement it in our program.
% Set temporary variables
rho = 1 - pi/(2*N);
mu0 = 1;
mu1 = rho;
% Set initial guess u0
u0 = [...];
% Perform 1 iteration of SSOR
u1 = [...];
% Perform the remaining iterations
for k = 2 : numIterations
mu = 1 / (2/(rho*mu1) - 1/mu0);
% Perform 1 iteration of SSOR
u = [...];
% Apply Chebyshev acceleration
u = 2*mu/(rho*mu1) * u - mu/mu0 * u0;
% Update temporary variables
mu0 = mu1;
mu1 = mu;
u0 = u1;
u1 = u;
end
Since SSOR uses SOR, we need to select the weight

which results in the following spectral radius:
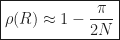
The rate of convergence does not seem to be different from that for SOR. However, with Chebyshev acceleration, we can multiply the error by 
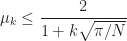
3. Example
Recall that our model problem uses the RHS function,

We choose 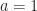


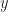
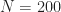
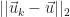
To compute the error 
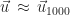
a. Results
After 100 iterations, we get the following solutions:
We can see that Gauss-Seidel is twice better than Jacobi. The amplitude of the Jacobi solution is about 0.40, while that of Gauss-Seidel is 0.64. The 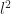
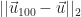
Next, let’s check the behavior of the
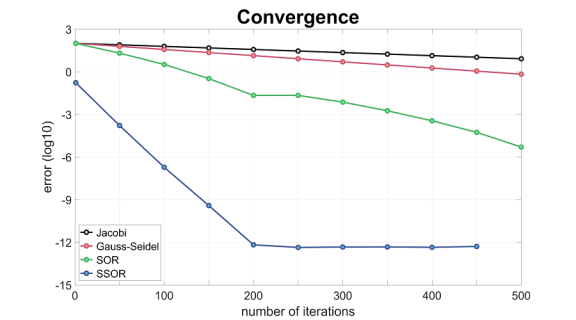
From the slopes, we see that the error for Gauss-Seidel decreases twice as fast as that for Jacobi. However, even after 500 iterations, the errors remain large. In comparison, the error for SOR almost reaches 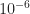

b. What if
I mentioned that, for optimal convergence, we want to follow red-black ordering for Gauss-Seidel and SOR, and to add Chebyshev acceleration to SSOR. Let’s see what happens if we follow natural ordering for Gauss-Seidel and SOR, and perform SSOR without Chebyshev acceleration.
After 100 iterations, the SOR solution is perhaps graphically the most different. We see a funny oscillation on the right part of the domain, perhaps because we traversed the points from left to right. (I would have suspected the left side to be less accurate, and wonder if I reversed the graph by mistake.) The oscillation goes away as we increase the number of iterations, but is undesirable in the first place.
If we look at the convergence plot, we can understand even better why we should not use natural ordering for SOR or omit Chebyshev acceleration for SSOR.
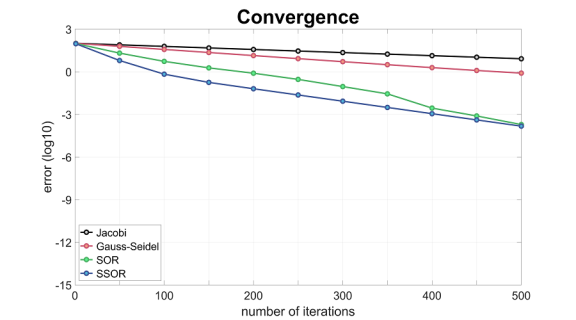
This time, the error for SOR only reaches 
![\omega = \left\{\begin{array}{ll} \displaystyle\frac{2}{1 + \sin(h\pi)}, & \mbox{for SOR} \\[20pt] \displaystyle\frac{2}{1 + \sqrt{2 - 2\cos(h\pi)}}, & \mbox{for SSOR} \end{array}\right.](https://s0.wp.com/latex.php?latex=%5Comega+%3D+%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bll%7D+%5Cdisplaystyle%5Cfrac%7B2%7D%7B1+%2B+%5Csin%28h%5Cpi%29%7D%2C+%26+%5Cmbox%7Bfor+SOR%7D+%5C%5C%5B20pt%5D+%5Cdisplaystyle%5Cfrac%7B2%7D%7B1+%2B+%5Csqrt%7B2+-+2%5Ccos%28h%5Cpi%29%7D%7D%2C+%26+%5Cmbox%7Bfor+SSOR%7D+%5Cend%7Barray%7D%5Cright.&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Notes
In short, use SSOR with Chebyshev acceleration. In addition to solving equations, SSOR makes a great preconditioner. Next time, we will look at Conjugate Gradient method, which is useful when the matrix is symmetric, positive definite (SPD).
You can find the code in its entirety here:
References
[1] James Demmel, Applied Numerical Linear Algebra (1997), 279-299.
[2] Isaac Lee, lecture notes (2011).
[3] John Sheldon, On the Numerical Solution of Elliptic Difference Equations, Mathematical Tables and Other Aids to Computation 9 (1955), 101-112.
[4] Qiang Ye, lecture notes (2009).
