
In numerical linear algebra, we create ways for a computer to solve a linear system of equations 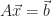
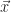
Perturbation theory concerns how much error we incur in the solution 
I will define and prove the statement, and help you understand it by “hearing” it.
1. Problem statement
Let’s consider the equation,
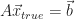
where 
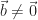


Suppose, instead, we solve the perturbed system,

We seek to find a bound on the error 
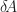

Given an induced matrix norm 

Note that we always have 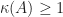
We will show that, under a mild assumption 

The RHS is a product of terms, so we can conclude two things. (1) If 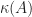
We see that the condition number influences how much change occurs in the output when we change the input of a system. As a result, we say that the matrix
2. Mathematical proof
a. Step 1
For any matrix
with
, the following statements hold:
(i)
is nonsingular, and its inverse is given by
.
(ii)
.
To prove (i), we check that 
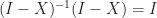
We see that,
![\begin{aligned} (I - X)(I - X)^{-1} &= (I - X)(I + X + X^{2} + \cdots) \\[12pt] &= (I + X + X^{2} + \cdots) - (X + X^{2} + X^{3} + \cdots) \\[12pt] &= I. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%28I+-+X%29%28I+-+X%29%5E%7B-1%7D+%26%3D+%28I+-+X%29%28I+%2B+X+%2B+X%5E%7B2%7D+%2B+%5Ccdots%29+%5C%5C%5B12pt%5D+%26%3D+%28I+%2B+X+%2B+X%5E%7B2%7D+%2B+%5Ccdots%29+-+%28X+%2B+X%5E%7B2%7D+%2B+X%5E%7B3%7D+%2B+%5Ccdots%29+%5C%5C%5B12pt%5D+%26%3D+I.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Note, to be rigorous, we would first show that the infinite series 

Let’s prove (ii). By triangle inequality and the properties of an induced matrix norm,
![\begin{aligned} ||(I - X)^{-1}|| &= ||I + X + X^{2} + \cdots|| \\[12pt] &\leq ||I|| + ||X|| + ||X^{2}|| + \cdots \\[12pt] &\leq ||I|| + ||X|| + ||X||^{2} + \cdots. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%7C%7C%28I+-+X%29%5E%7B-1%7D%7C%7C+%26%3D+%7C%7CI+%2B+X+%2B+X%5E%7B2%7D+%2B+%5Ccdots%7C%7C+%5C%5C%5B12pt%5D+%26%5Cleq+%7C%7CI%7C%7C+%2B+%7C%7CX%7C%7C+%2B+%7C%7CX%5E%7B2%7D%7C%7C+%2B+%5Ccdots+%5C%5C%5B12pt%5D+%26%5Cleq+%7C%7CI%7C%7C+%2B+%7C%7CX%7C%7C+%2B+%7C%7CX%7C%7C%5E%7B2%7D+%2B+%5Ccdots.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Next, we use the infinite geometric sum formula: For any real number 

Since 
■
b. Step 2
Recall that
Then,
is also nonsingular.
Since

Hence, 
We find that,
![\displaystyle\begin{aligned} ||A^{-1}\delta\!A|| &\leq ||A^{-1}|| \cdot ||\delta\!A|| \\[12pt] &= \kappa(A)\frac{||\delta\!A||}{||A||} \\[12pt] &< 1. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Cbegin%7Baligned%7D+%7C%7CA%5E%7B-1%7D%5Cdelta%5C%21A%7C%7C+%26%5Cleq+%7C%7CA%5E%7B-1%7D%7C%7C+%5Ccdot+%7C%7C%5Cdelta%5C%21A%7C%7C+%5C%5C%5B12pt%5D+%26%3D+%5Ckappa%28A%29%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D+%5C%5C%5B12pt%5D+%26%3C+1.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Hence,
■
Before we move on, let’s read the statement in Step 2 again. It tells us that, if a matrix is nonsingular, then there are infinitely many matrices nearby that are nonsingular, too. (And infinitely many around them, and so on.) This supports the fact that there are far more nonsingular matrices than singular ones. Isn’t that a marvel?
c. Step 3
Show that,
.
We’re almost there! Recall the original problems:
![\begin{array}{rcl} A\vec{x}_{true} & = & \vec{b} \\[12pt] (A + \delta\!A)\vec{x} & = & \vec{b} + \vec{\delta b}. \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Brcl%7D+A%5Cvec%7Bx%7D_%7Btrue%7D+%26+%3D+%26+%5Cvec%7Bb%7D+%5C%5C%5B12pt%5D+%28A+%2B+%5Cdelta%5C%21A%29%5Cvec%7Bx%7D+%26+%3D+%26+%5Cvec%7Bb%7D+%2B+%5Cvec%7B%5Cdelta+b%7D.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Subtract the two equations to get,
![\begin{array}{ll} & (A + \delta\!A)\vec{x} - A\vec{x}_{true} = \vec{\delta b} \\[12pt] \Rightarrow & (A + \delta\!A)(\vec{x} - \vec{x}_{true}) = \vec{\delta b} - \delta\!A\vec{x}_{true} \\[12pt] \Rightarrow & \vec{x} - \vec{x}_{true} = (A + \delta\!A)^{-1}(\vec{b} - \delta\!A\vec{x}_{true}). \end{array}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Barray%7D%7Bll%7D+%26+%28A+%2B+%5Cdelta%5C%21A%29%5Cvec%7Bx%7D+-+A%5Cvec%7Bx%7D_%7Btrue%7D+%3D+%5Cvec%7B%5Cdelta+b%7D+%5C%5C%5B12pt%5D+%5CRightarrow+%26+%28A+%2B+%5Cdelta%5C%21A%29%28%5Cvec%7Bx%7D+-+%5Cvec%7Bx%7D_%7Btrue%7D%29+%3D+%5Cvec%7B%5Cdelta+b%7D+-+%5Cdelta%5C%21A%5Cvec%7Bx%7D_%7Btrue%7D+%5C%5C%5B12pt%5D+%5CRightarrow+%26+%5Cvec%7Bx%7D+-+%5Cvec%7Bx%7D_%7Btrue%7D+%3D+%28A+%2B+%5Cdelta%5C%21A%29%5E%7B-1%7D%28%5Cvec%7Bb%7D+-+%5Cdelta%5C%21A%5Cvec%7Bx%7D_%7Btrue%7D%29.+%5Cend%7Barray%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Take the vector norm to both sides:
![\begin{aligned} ||\vec{x} - \vec{x}_{true}|| &= ||(A + \delta\!A)^{-1}(\vec{b} - \delta\!A\vec{x}_{true})|| \\[12pt] &\leq ||(A + \delta\!A)^{-1}|| \cdot ||\vec{b} - \delta\!A\vec{x}_{true}|| \\[12pt] & \leq ||(A + \delta\!A)^{-1}|| \cdot \Bigl(||\vec{b}|| + ||\delta\!A|| \cdot ||\vec{x}_{true}||\Bigr). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%7C%7C%5Cvec%7Bx%7D+-+%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C+%26%3D+%7C%7C%28A+%2B+%5Cdelta%5C%21A%29%5E%7B-1%7D%28%5Cvec%7Bb%7D+-+%5Cdelta%5C%21A%5Cvec%7Bx%7D_%7Btrue%7D%29%7C%7C+%5C%5C%5B12pt%5D+%26%5Cleq+%7C%7C%28A+%2B+%5Cdelta%5C%21A%29%5E%7B-1%7D%7C%7C+%5Ccdot+%7C%7C%5Cvec%7Bb%7D+-+%5Cdelta%5C%21A%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C+%5C%5C%5B12pt%5D+%26+%5Cleq+%7C%7C%28A+%2B+%5Cdelta%5C%21A%29%5E%7B-1%7D%7C%7C+%5Ccdot+%5CBigl%28%7C%7C%5Cvec%7Bb%7D%7C%7C+%2B+%7C%7C%5Cdelta%5C%21A%7C%7C+%5Ccdot+%7C%7C%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C%5CBigr%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Finally, we divide both sides by 
■
d. Step 4
Finally, prove that,
.
Let’s find an upper bound for 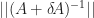
![\begin{aligned} ||(A + \delta\!A)^{-1}|| &\leq ||(I + A^{-1}\delta\!A)^{-1}|| \cdot ||A^{-1}|| \\[12pt] &\leq \frac{||A^{-1}||}{1 - ||A^{-1}\delta\!A||} \\[12pt] &\leq \frac{||A^{-1}||}{1 - \kappa(A)\frac{||\delta\!A||}{||A||}}. \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%7C%7C%28A+%2B+%5Cdelta%5C%21A%29%5E%7B-1%7D%7C%7C+%26%5Cleq+%7C%7C%28I+%2B+A%5E%7B-1%7D%5Cdelta%5C%21A%29%5E%7B-1%7D%7C%7C+%5Ccdot+%7C%7CA%5E%7B-1%7D%7C%7C+%5C%5C%5B12pt%5D+%26%5Cleq+%5Cfrac%7B%7C%7CA%5E%7B-1%7D%7C%7C%7D%7B1+-+%7C%7CA%5E%7B-1%7D%5Cdelta%5C%21A%7C%7C%7D+%5C%5C%5B12pt%5D+%26%5Cleq+%5Cfrac%7B%7C%7CA%5E%7B-1%7D%7C%7C%7D%7B1+-+%5Ckappa%28A%29%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D%7D.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Hence,
![\begin{aligned} \frac{||\vec{x} - \vec{x}_{true}||}{||\vec{x}_{true}||} &\leq \frac{||A|| \cdot ||A^{-1}||}{1 - \kappa(A)\frac{||\delta\!A||}{||A||}} \,\cdot \left(\frac{||\delta\!A||}{||A||} + \frac{||\vec{\delta b}||}{||A|| \cdot ||\vec{x}_{true}||}\right) \\[12pt] &\leq \frac{\kappa(A)}{1 - \kappa(A)\frac{||\delta\!A||}{||A||}} \,\cdot \left(\frac{||\delta\!A||}{||A||} + \frac{||\vec{\delta b}||}{||\vec{b}||}\right). \end{aligned}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Baligned%7D+%5Cfrac%7B%7C%7C%5Cvec%7Bx%7D+-+%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C%7D%7B%7C%7C%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C%7D+%26%5Cleq+%5Cfrac%7B%7C%7CA%7C%7C+%5Ccdot+%7C%7CA%5E%7B-1%7D%7C%7C%7D%7B1+-+%5Ckappa%28A%29%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D%7D+%5C%2C%5Ccdot+%5Cleft%28%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D+%2B+%5Cfrac%7B%7C%7C%5Cvec%7B%5Cdelta+b%7D%7C%7C%7D%7B%7C%7CA%7C%7C+%5Ccdot+%7C%7C%5Cvec%7Bx%7D_%7Btrue%7D%7C%7C%7D%5Cright%29+%5C%5C%5B12pt%5D+%26%5Cleq+%5Cfrac%7B%5Ckappa%28A%29%7D%7B1+-+%5Ckappa%28A%29%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D%7D+%5C%2C%5Ccdot+%5Cleft%28%5Cfrac%7B%7C%7C%5Cdelta%5C%21A%7C%7C%7D%7B%7C%7CA%7C%7C%7D+%2B+%5Cfrac%7B%7C%7C%5Cvec%7B%5Cdelta+b%7D%7C%7C%7D%7B%7C%7C%5Cvec%7Bb%7D%7C%7C%7D%5Cright%29.+%5Cend%7Baligned%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
■
3. Application
We can represent an audio as a vector 
For computational efficiency, we will write 

Next, we apply a nonsingular matrix 


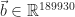
From now on, we assume that we only have 
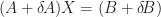
a. Generating matrices
To generate a well-conditioned 
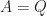

For an ill-conditioned 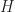
![H = \left[\begin{array}{ccccc} 1 & \frac{1}{2} & \cdots & \frac{1}{9} & \frac{1}{10} \\[12pt] \frac{1}{2} & \frac{1}{3} & \cdots & \frac{1}{10} & \frac{1}{11} \\[12pt] \vdots & \vdots & \ddots & \vdots & \vdots \\[12pt] \frac{1}{9} & \frac{1}{10} & \cdots & \frac{1}{17} & \frac{1}{18} \\[12pt] \frac{1}{10} & \frac{1}{11} & \cdots & \frac{1}{18} & \frac{1}{19} \end{array}\right]](https://s0.wp.com/latex.php?latex=H+%3D+%5Cleft%5B%5Cbegin%7Barray%7D%7Bccccc%7D+1+%26+%5Cfrac%7B1%7D%7B2%7D+%26+%5Ccdots+%26+%5Cfrac%7B1%7D%7B9%7D+%26+%5Cfrac%7B1%7D%7B10%7D+%5C%5C%5B12pt%5D+%5Cfrac%7B1%7D%7B2%7D+%26+%5Cfrac%7B1%7D%7B3%7D+%26+%5Ccdots+%26+%5Cfrac%7B1%7D%7B10%7D+%26+%5Cfrac%7B1%7D%7B11%7D+%5C%5C%5B12pt%5D+%5Cvdots+%26+%5Cvdots+%26+%5Cddots+%26+%5Cvdots+%26+%5Cvdots+%5C%5C%5B12pt%5D+%5Cfrac%7B1%7D%7B9%7D+%26+%5Cfrac%7B1%7D%7B10%7D+%26+%5Ccdots+%26+%5Cfrac%7B1%7D%7B17%7D+%26+%5Cfrac%7B1%7D%7B18%7D+%5C%5C%5B12pt%5D+%5Cfrac%7B1%7D%7B10%7D+%26+%5Cfrac%7B1%7D%7B11%7D+%26+%5Ccdots+%26+%5Cfrac%7B1%7D%7B18%7D+%26+%5Cfrac%7B1%7D%7B19%7D+%5Cend%7Barray%7D%5Cright%5D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
Then, 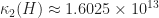
b. Generating perturbations
The entries of perturbations 
We are more interested in ensuring that the values of 
c. Simulations
We can run perturbation_theory.m under 6 different cases:
![\begin{tabular}{c|c|c|c} & Perturb A only & Perturb B only & Perturb A and B \\[8pt]\hline Well-conditioned A & (1,\,1) & (1,\,2) & (1,\,3) \\[8pt]\hline Ill-conditioned A & (2,\,1) & (2,\,2) & (2,\,3) \end{tabular}](https://s0.wp.com/latex.php?latex=%5Cbegin%7Btabular%7D%7Bc%7Cc%7Cc%7Cc%7D+%26+Perturb+A+only+%26+Perturb+B+only+%26+Perturb+A+and+B+%5C%5C%5B8pt%5D%5Chline+Well-conditioned+A+%26+%281%2C%5C%2C1%29+%26+%281%2C%5C%2C2%29+%26+%281%2C%5C%2C3%29+%5C%5C%5B8pt%5D%5Chline+Ill-conditioned+A+%26+%282%2C%5C%2C1%29+%26+%282%2C%5C%2C2%29+%26+%282%2C%5C%2C3%29+%5Cend%7Btabular%7D&bg=ffffff&fg=1a1a1a&s=0&c=20201002)
The table lists the input parameters for each case.
First, let’s consider what happens when
These plots show that the obtained solution
Download and listen to the obtained audios:
- audio_obtained11.wav (well-conditioned
- audio_obtained12.wav (well-conditioned
- audio_obtained13.wav (well-conditioned
Next, let’s consider what happens when
This time, the obtained solution hardly matches the true solution. You can hear much more noise in the obtained audios, and listening to them becomes almost unbearable. The relative error is orders of magnitude larger. It’s interesting how perturbing
Download and listen to the obtained audios:
- audio_obtained21.wav (ill-conditioned
- audio_obtained22.wav (ill-conditioned
- audio_obtained23.wav (ill-conditioned
We can also check that our matrices satisfy the statement that we painstakingly proved. I will leave writing the extra code to you.
Notes
Given a vector norm 
The induced matrix norm of

Hence, the induced matrix norm measures how far out we can map a vector relative to its original size. We can also generalize the definition to rectangular matrices.
Because of its definition, the induced matrix norm satisfies these useful properties:
(i) For any 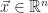
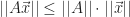
(ii) For any 
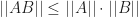
In particular, property (ii) implies that the condition number of a nonsingular matrix is always at least 1.
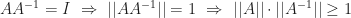
You can find the code and audio files in their entirety here:
Download from GitHub
